Study Log (2020.01)
2020-01-30
- Reinforcement Learning
- Chapter 12. Eligibility Traces
- 12.5 True Online TD(��$\lambda$)
- 12.6 Dutch Traces in Monte Carlo Learning
- 12.7 Sarsa(�$\lambda$)
- Sarsa(�$\lambda$) with binary features and linear function approximation
- True online Sarsa(�$\lambda$)
- 12.8 Variable �$\lambda$ and �$\gamma$
- 12.9 Off-policy Traces with Control Variates
- 12.10 Watkins’s Q(�$\lambda$�) to Tree-Backup(��$\lambda$)
- 12.11 Stable Off-policy Methods with Traces
- Page #316
- Chapter 12. Eligibility Traces
2020-01-27
- Reinforcement Learning
- Chapter 12. Eligibility Traces
- 12.3 n-step Truncated ���$\lambda$-return Methods
- 12.4 Redoing Updates: Online �$\lambda$-return Algorithm
- Page #299
- Chapter 12. Eligibility Traces
- 팡요랩
- Lecture #4
- Lecture #5
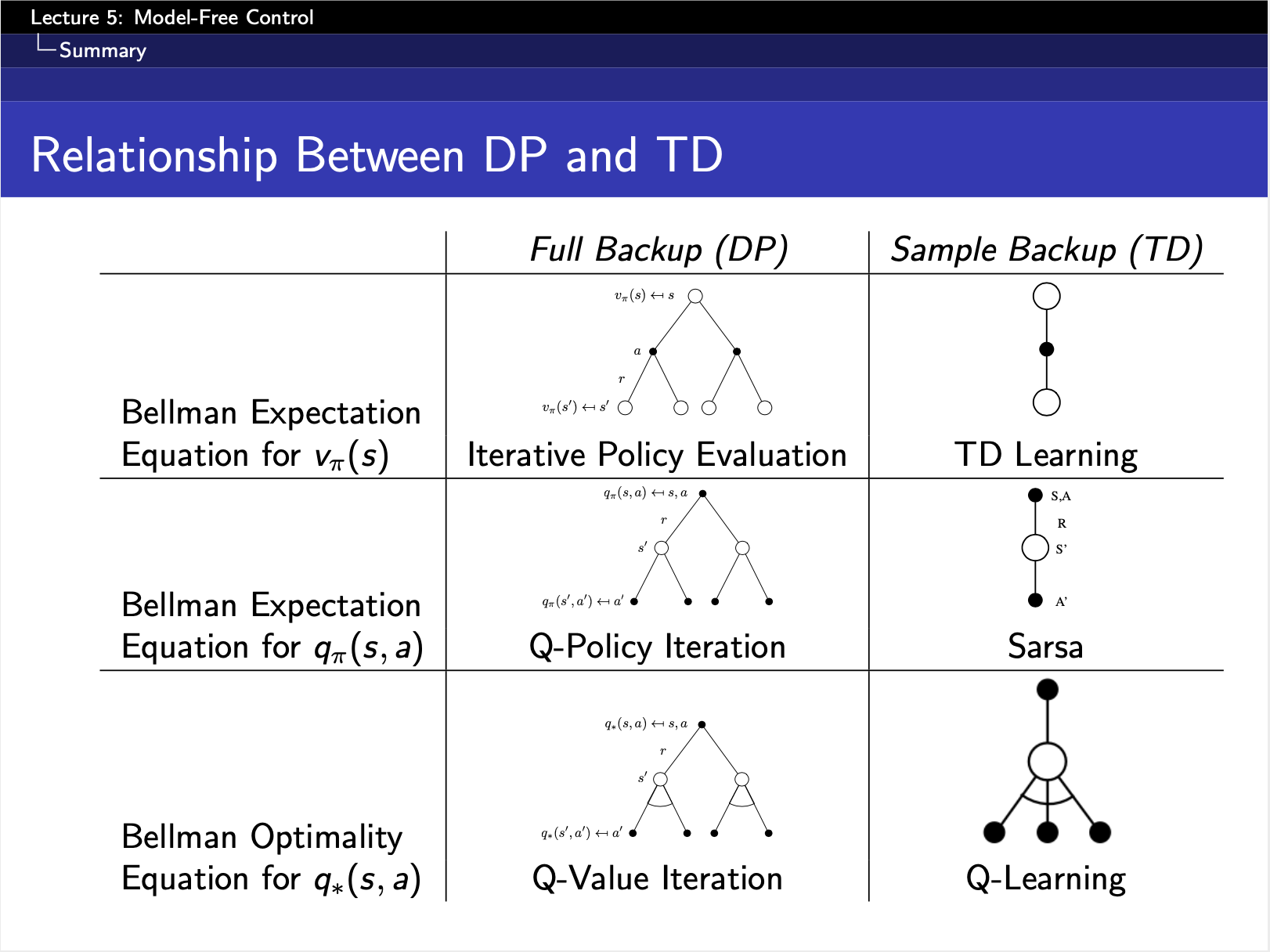

2020-01-25
- 모두를 위한 머신러닝/딥러닝 강의
- Lecture #45) ML lab12-4: Stacked RNN + Softmax Layer
- Lecture #46
- Lecture #47) ML lab12-6: RNN with Time Series Data : Step별 Moving 예측에 사용 가능
- Lecture #48
- Lecture #49
- Lecture #50
- Lecture #51
2020-01-24
- Reinforcement Learning
- Chapter 12. Eligibility Traces
- 12.2 TD(��$\lambda$)
- Page #295
- Chapter 12. Eligibility Traces
- 팡요랩
- Lecture #3
2020-01-23
- Reinforcement Learning
- Chapter 12. Eligibility Traces
- 12.1 The �$\lambda$-return
- Page #292
- Chapter 12. Eligibility Traces
- 팡요랩
- Lecture #2
2020-01-22
- Reinforcement Learning
- Chapter 11. Off-policy Methods with Approximation
- 11.7 Gradient-TD Methods
- 11.8 Emphatic-TD Methods
- 11.9 Reducing Variance
- 11.10 Summary
- Page #287
- Chapter 11. Off-policy Methods with Approximation
- 팡요랩
- Lecture #1
2020-01-21
- Reinforcement Learning
- Chapter 11. Off-policy Methods with Approximation
- 11.6 The Bellman Error is Not Learnable
- Page #278
- Chapter 11. Off-policy Methods with Approximation
2020-01-20
- Reinforcement Learning
- Chapter 11. Off-policy Methods with Approximation
- 11.2 Examples of Off-policy Divergence
- 11.3 The Deadly Triad
- 11.4 Linear Value-function Geometry
- 11.5 Gradient Descent in the Bellman Error
- Page #272
- Chapter 11. Off-policy Methods with Approximation
2020-01-19
- Reinforcement Learning
- Chapter 11. Off-policy Methods with Approximation
- 11.2 Examples of Off-policy Divergence
- Page #263
- Chapter 11. Off-policy Methods with Approximation
2020-01-18
- Reinforcement Learning
- Chapter 11. Off-policy Methods with Approximation
- 11.2 Examples of Off-policy Divergence
- Page #262
- Chapter 11. Off-policy Methods with Approximation
2020-01-17
- Reinforcement Learning
- Chapter 11. Off-policy Methods with Approximation
- 11.1 Semi-gradient Methods
- 11.2 Examples of Off-policy Divergence
- Page #260
- Chapter 11. Off-policy Methods with Approximation
2020-01-16
- Reinforcement Learning
- Chapter 10. On-policy Control with Approximation
- 10.5 Differential Semi-gradient n-step Sarsa
- 10.6 Summary
- Page #257
- Chapter 10. On-policy Control with Approximation
2020-01-15
- Reinforcement Learning
- Chapter 10. On-policy Control with Approximation
- 10.3 Average Reward: A New Problem Setting for Continuing Tasks
- 10.4 Deprecating the Discounted Setting
- Page #255
- Chapter 10. On-policy Control with Approximation
2020-01-14
- Reinforcement Learning
- Chapter 10. On-policy Control with Approximation
- 10.2 Semi-gradient n-step Sarsa
- 10.3 Average Reward: A New Problem Setting for Continuing Tasks
- Page #252
- Chapter 10. On-policy Control with Approximation
2020-01-13
- Reinforcement Learning
- Chapter 9. On-policy Prediction with Approximation
- 9.9 Memory-based Function Approximation
- 9.10 Kernel-based Function Approximation
- 9.11 Looking Deeper at On-policy Learning: Interest and Emphasis
- 9.12 Summary
- Chapter 10. On-policy Control with Approximation
- 10.1 Episodic Semi-gradient Control
- 10.2 Semi-gradient n-step Sarsa
- Page #247
- Chapter 9. On-policy Prediction with Approximation
2020-01-11
- Reinforcement Learning
- Chapter 9. On-policy Prediction with Approximation
- 9.7 Nonlinear Function Approximation: Artificial Neural Networks
- 9.8 Least-Squares TD
- Page #228
- Chapter 9. On-policy Prediction with Approximation
2020-01-10
- Reinforcement Learning
- Chapter 9. On-policy Prediction with Approximation
- 9.5 Feature Construction for Linear Methods
- 9.5.5 Radial Basis Functions
- 9.6 Selecting Step-Size Parameters Manually
- 9.5 Feature Construction for Linear Methods
- Page #223
- Chapter 9. On-policy Prediction with Approximation
2020-01-09
- Reinforcement Learning
- Chapter 9. On-policy Prediction with Approximation
- 9.5 Feature Construction for Linear Methods
- 9.5.4 Tile Coding
- 9.5 Feature Construction for Linear Methods
- Page #220
- Chapter 9. On-policy Prediction with Approximation
- Feature Construction for Linear Methods
2020-01-08
- Reinforcement Learning
- Chapter 9. On-policy Prediction with Approximation
- 9.4 Linear Methods
- 9.5 Feature Construction for Linear Methods
- 9.5.1 Polynomials
- 9.5.2 Fourier Basis
- 9.5.3 Coarse Coding
- Page #217
- Chapter 9. On-policy Prediction with Approximation
2020-01-07
- Reinforcement Learning
- Chapter 9. On-policy Prediction with Approximation
- 9.3 Stochastic-gradient and Semi-gradient Methods
- 9.4 Linear Methods
- Page #205
- Chapter 9. On-policy Prediction with Approximation
- 모두를 위한 머신러닝/딥러닝 강의
- Lecture #42) ML lab12-1: RNN - Basics
- Lecture #43
- Lecture #44
2020-01-06
- Reinforcement Learning
- Chapter 9. On-policy Prediction with Approximation
- 9.2 The Prediction Objective (VE)
- 9.3 Stochastic-gradient and Semi-gradient Methods
- Page #204
- Chapter 9. On-policy Prediction with Approximation
2020-01-05
- Reinforcement Learning
- Chapter 9. On-policy Prediction with Approximation
- 9.1 Value-function Approximation
- Page #199
- Chapter 9. On-policy Prediction with Approximation
2020-01-04
- Reinforcement Learning
- Chapter 8. Planning and Learning with Tabular Methods
- 8.7 Real-time Dynamic Programming
- 8.8 Planning at Decision Time
- 8.9 Heuristic Search
- 8.10 Rollout Algorithms
- 8.11 Monte Carlo Tree Search
- 8.12 Summary of the Chapter
- 8.13 Summary of Part I: Dimensions
- Page #195
- Chapter 8. Planning and Learning with Tabular Methods
2020-01-03
- Reinforcement Learning
- Chapter 8. Planning and Learning with Tabular Methods
- 8.5 Expected vs. Sample Updates
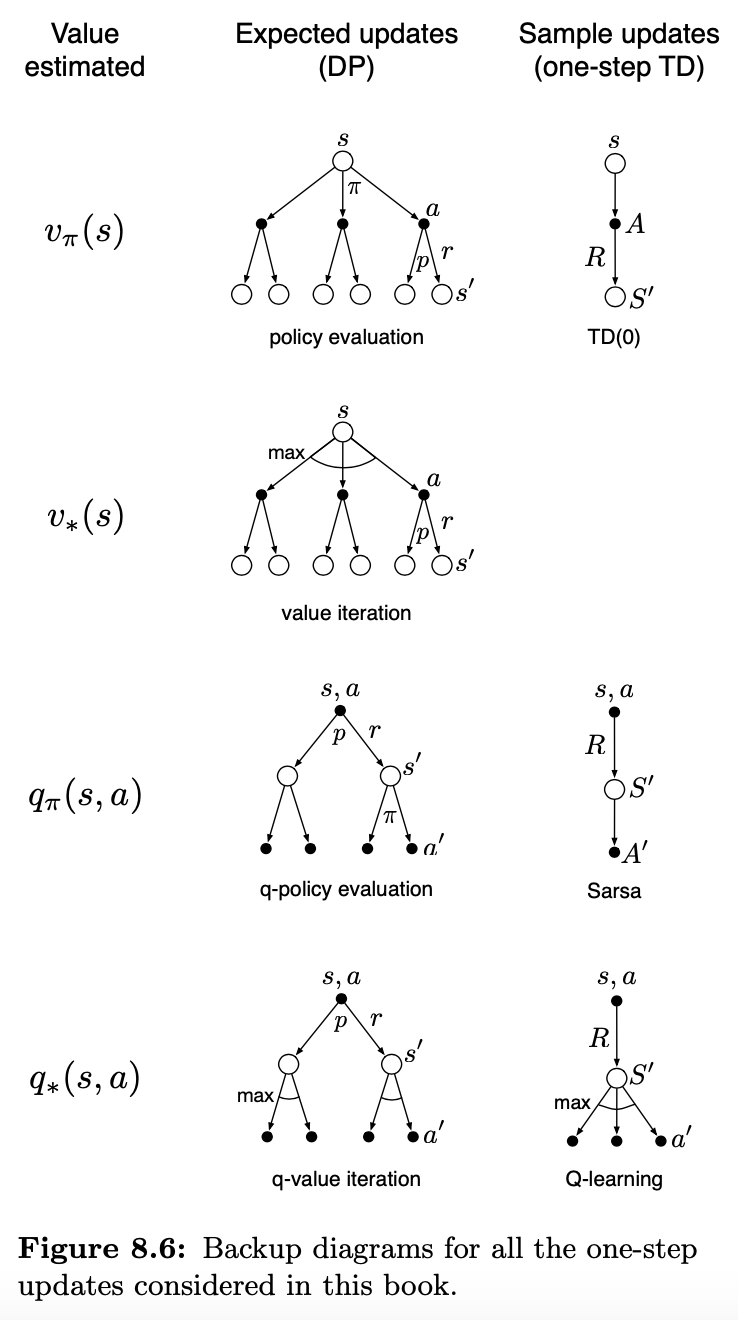
- 8.6 Trajectory Sampling
- 8.7 Real-time Dynamic Programming
- 8.5 Expected vs. Sample Updates
- Page #179
- Chapter 8. Planning and Learning with Tabular Methods
2020-01-02
- Reinforcement Learning
- Chapter 8. Planning and Learning with Tabular Methods
- 8.4 Prioritized Sweeping
- 8.5 Expected vs. Sample Updates
- Page #173
- Chapter 8. Planning and Learning with Tabular Methods
2020-01-01
- Reinforcement Learning
- Chapter 8. Planning and Learning with Tabular Methods
- 8.3 When the Model Is Wrong
- 8.4 Prioritized Sweeping
- Page #172
- Chapter 8. Planning and Learning with Tabular Methods
Template
- Fundamental of Reinforcement Learning
- Chapter #.
- 모두를 위한 머신러닝/딥러닝 강의
- Lecture #.
- UCL Course on RL
- Lecture #.
- Reinforcement Learning
- Page #.
- 팡요랩
- Lecture #.
- Pattern Recognition & Machine Learning
Comments